
Windows Server Failover Clusters (WSFC), formerly called Microsoft Cluster Service (MSCS), is a clustering technology of Windows Server that allows you to run multiple Windows Servers in a cluster configuration. There is a variety of use cases to use such high availability configuration like SQL database, DFS namespace, file server… Windows clusters were particularly popular when virtualization was not as common as it is today. You could run several physical servers in high availability which is a huge thing for a service. vSphere has been offering the possibility to run virtual Windows failover cluster nodes for many years now and the latest version of vSphere even includes the ability to migrate a node to another host while it is running.
In this article we will focus on the storage aspect of virtualized Windows clusters and how it affects the boot time of an ESXi host.
Technical background
VMFS background
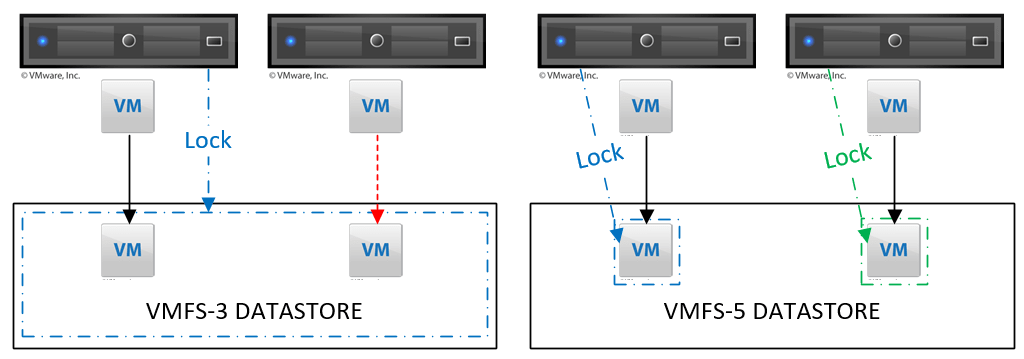
In VMFS version 3, whenever a virtual machine wanted to write to its disk stored on a datastore, the ESXi host would issue an SCSI-3 reservation on the LUN itself, preventing any other host to write to it at the same time, incurring latency concerns in the environment. This locking mechanism was replaced in VMFS 5 by a per-vmdk lock which allows multiple hosts to write to the same datastore concurrently. Any SCSI-3 reservation commands will be intercepted and dropped by the file system (VMFS 5).

WSFC/MSCS shared disks
The failover mechanism of MSCS relies on the use of shared volumes for data and a smaller shared volume called quorum that is used to determine the health of the cluster. There is one active node for each clustered role and the others are passive nodes, waiting to take over in case of planned or unplanned failover. One of the specifics of Windows clusters is that the active node holds a persistent SCSI-3 reservation on the shared volumes (hence the LUN). Because of what we mentioned in the previous chapter, it is required to use Raw Device Mapping (RDM) disks in physical mode to allow the active node to lock the LUN. Once the active node is running and the LUN is locked, no other host can write to it, this is to prevent data corruption.
ESXi boot time issue
As part of its boot process, ESXi will scan the storage and try to access the LUNs to gather information about them. Now like we suggested earlier, if a WSFC active node is currently holding an lock on a LUN that is also presented to the booting host, it will not be able to access that LUN and keep trying until it decides to move on to the next one. The issue here is that it takes quite some time before doing so and the more WSFC enabled LUNs you have, the longer it will take the ESXi host to complete its boot sequence. It can take more than 1 hour to boot with many RDM compared to a few minutes with none or the right setting configured (more on this later).
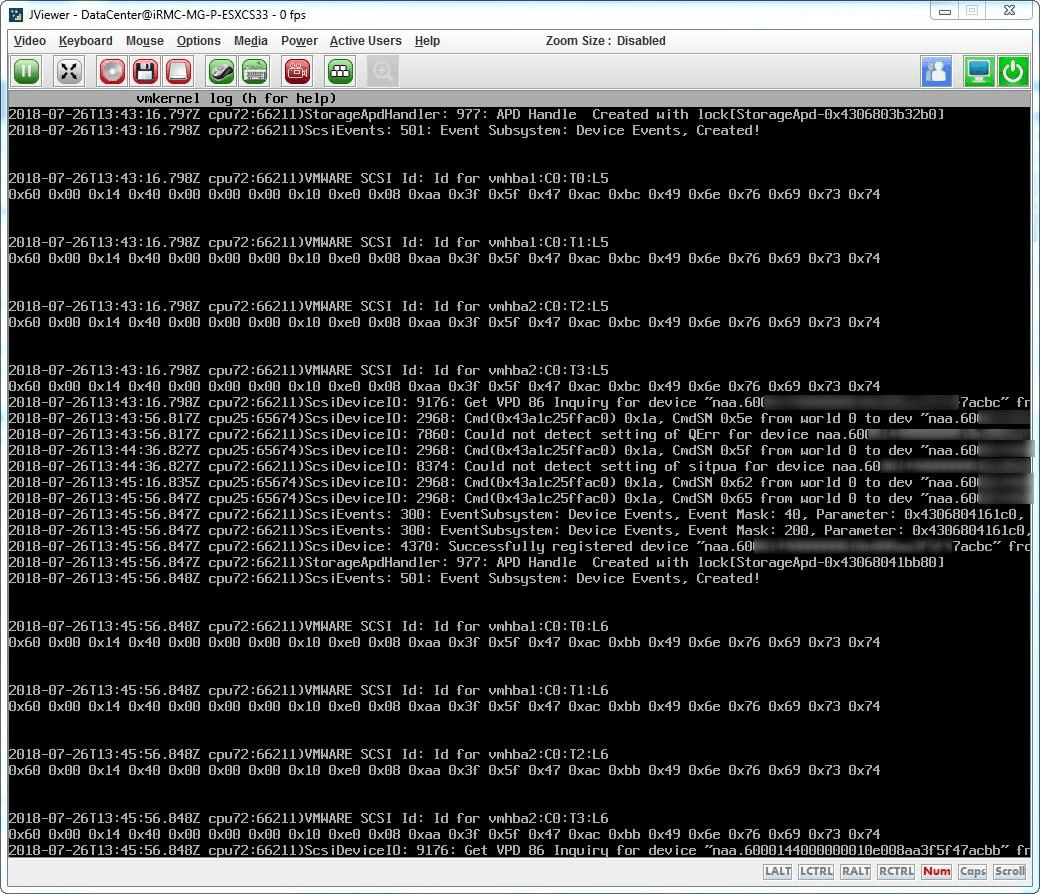
If you press ALT+F12 during the boot sequence to display the vmkernel log, you will see message like these ones:
How to fix it
We need to tell ESXi that the LUNs used in an MSCS cluster are always reserved so it will not bother trying to access them. In order to do this, we will use esxcli to flag the LUNs as “Perennially reserved“.
Note that you should not enable this flag on LUNs that are hosting a VMFS datastore.
Shell / SSH
First find the LUNs’ canonical name (naa.). It will be easier using PowerCLI than the web client as you can see the ScsciCanonicalName property of the hard disks attached to a virtual machine.
PS> Get-VM MSCS-Node-1 | Get-HardDisk -DiskType RawPhysical | select scsicanonicalname
ScsiCanonicalName
—————–
naa.60001xxxxxxxxxxxxxxxxxxxxxxxacbc
naa.60001xxxxxxxxxxxxxxxxxxxxxxxacbb
naa.60001xxxxxxxxxxxxxxxxxxxxxxxacba
naa.60001xxxxxxxxxxxxxxxxxxxxxxxacbd
naa.60001xxxxxxxxxxxxxxxxxxxxxxxacb9
naa.60001xxxxxxxxxxxxxxxxxxxxxxxacb8
Connect to the ESXi host using SSH or with the console
This method is good if you only have a few hosts with few RDMs but it will become very cumbersome as you scale. You also need to be sure about the naa names. The next method uses PowerCLI, it is a lot more efficient and less error prone.
PowerCLI
The easier method is to use PowerCLI to set the Perennially reserved flag. The function provided below the examples takes RDM Hard Disk objects as parameter so there is no risk of selecting a LUN hosting a VMFS datastore. The script will take care of finding the canonical name and setting the flag using the Get-EsxCLI -V2 cmdlet.
Example 1:
Set the flag to true all the RDM LUNs of the VMs matching MSCS-Node-* on all the vSphere hosts.
Example 2:
If you only use RDM disks for MSCS cluster then you most likely want to flag the LUNs of any RDM disks present in your cluster. The below will set the flag to true on all the RDM disks on all the hosts.
The PowerCLI function
Function Set-PerenniallyReserved {
param(
)
# Loop each host
foreach ($esx in $VMHost) {
Write-Output “—– Processing $($esx.name)”
# Prepare esxcli
$EsxCLI = Get-EsxCli -VMHost $esx -V2
$ArgList = $EsxCLI.storage.core.device.list.CreateArgs()
$ArgSet = $EsxCLI.storage.core.device.SetConfig.CreateArgs()
$ArgSet.perenniallyreserved = $PerenniallyReserved
# loop each disk in current host
foreach ($disk in $HardDisk) {
$ArgList.device = $ArgSet.device = $disk.ScsiCanonicalName
# Check if already in the required state otherwise change it
$ErrorActionPreference = “SilentlyContinue”
$PR = $EsxCLI.storage.core.device.list.Invoke($ArgList)
$ErrorActionPreference = “Continue”
if ($PR) {
# Check if already PR
$PR = $PR.IsPerenniallyReserved
if ($PR -eq $PerenniallyReserved) {
Write-Output “$($disk.ScsiCanonicalName) already in the expected state on $($esx.name) – Perennially reserved : $PR”
} else {
# Set perennially reserved on the lun
$exec = $EsxCLI.storage.core.device.SetConfig.Invoke($ArgSet)
$NewPR = $EsxCLI.storage.core.device.list.Invoke($ArgList).IsPerenniallyReserved
if ($PR -ne $NewPR) {
Write-Output “$($esx.name) – $($disk.ScsiCanonicalName) Perennially Reserved State changed : $PR => $NewPR”
} else {
Write-Warning “$($esx.name) – $($disk.ScsiCanonicalName) Perennially Reserved state unchanged : $PR => $NewPR”
}
}
} else {
Write-Warning “$($disk.ScsiCanonicalName) not found on $($esx.name)”
}
}
}
}
Benchmark
The following tests were done on a host with 10 RDM disks used in an MSCS cluster configuration.
| Perennially reserved | Initiate reboot | Host is not responding | Established a connection | Reboot time |
|---|---|---|---|---|
| TRUE | 15:01:53 | 15:03:45 | 15:08:49 | 00:05:04 |
| FALSE | 10:30:07 | 10:31:44 | 11:05:14 | 00:33:30 |
As you can see the host took more than 33 minutes to restart when the flag was off and just over 5 minutes with the flag on which accounts to more than 28 minutes faster. To put in perspective, if you had 20 hosts to patch one by one (which requires a reboot), it would make the process 9 hours and 30 minutes faster!
Conclusion
Although this issue has been around for a few years it is still a discovery for most of us as not everyone is used or gets to work with RDM disks.
Follow our Twitter and Facebook feeds for new releases, updates, insightful posts and more.