
Storage considerations when planning a Metro cluster
Metro clusters are one of these areas of virtualization often regarded as the holy grail for an infrastructure because they do provide shiny features like VM mobility across sites or disaster avoidance.
However, more often than not, the downsides of such design are disregarded or just ignored in order to get on the MSC train (Metro Storage Cluster). The issue being that a badly design Metro cluster can cause more harm than good and potentially be destructive to your data if not enough care is given to avoiding corruption.
Table of Contents
- What is a Metro Cluster?
- Metro-Cluster vs Share-Nothing
- Shared nothing
- Metro cluster
- 5 things to look out for when planning a Metro Cluster
- Geographic paths
- Latency on the ISL
- Uniform vs Non-uniform host access
- Use DRS
- Resources utilization
- Conclusion
What is a Metro Cluster?
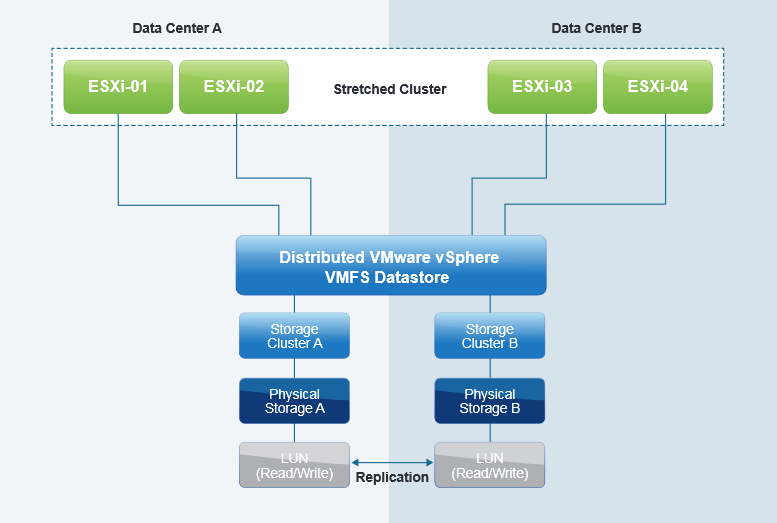
For those who are not familiar with it, a metro cluster is a host cluster that spans multiple sites located in different locations (usually two). The hosts may be in different data centers but still, access the same shared storage.
In order to achieve this, storage vendors offer proprietary software or hardware solutions that allow for synchronous block and cache replication of LUNs between storage arrays. Netapp’s metrocluster and EMC’s VPLEX are examples of such technology.

Like the name suggests (Metro), the different sites that make up these types of clusters are almost always located in the same area if not city due to latency requirements (more on this later).
Metro-Cluster vs Share-Nothing
As mentioned above, the greatest difference between a Metro-Cluster and a regular Cluster lies in the fact that the hosts of both sites see the same datastores presented by the storage provider.
We will only mention the difference in terms of availability between a shared-nothing and a Metro-Cluster configuration here to serve as an example.
Shared nothing
In a shared-nothing multi-site design, there are multiple applications to it but one of them usually is to use the second site as a DR site. Meaning, you use it to store replicas of the VMs you want to protect using SRM or the likes and run a secondary DC, DNS, … Of course, you can always run some test or non-prod workloads to make use of the resources but this is out of the scope here.

If a failure occurs on site A in this type of scenario, you will need to restore (Power On) all your VMs on the second site which can involve a long RTO according to your processes and a long RPO according to how often you replicate your VMs or volumes.

Metro cluster
In a metro cluster configuration you will be able to run your workloads on any host regardless of the site it is in and leverage vSphere HA to automatically restart VMs on the surviving site. Of course you will need to be mindful of the stretched architecture in the way you distribute your VMs across the sites in order to reduce the traffic on the link, whether it is generated by the VMs accessing their storage on the SAN or the VMs talking to each other on the LAN (if they share it).

If configured properly, when you lose a site in a metro cluster configuration, the consequences are less important than in a share-nothing configuration as your service should still be running. If you have bad luck and some master DB server was running on the failed site you will have to wait for vSphere HA to restart it before the service comes back.
Because the storage is synchronized between the arrays, the VMs that went down with the site will be restarted by vSphere HA on the hosts in the surviving site.

5 things to look out for when planning a Metro Cluster
Geographic paths
The Inter-Site-Link is probably the most important component of a Metro Cluster. Especially if you share it using something like wavelength multiplexing on the fiber linking the sites. In this case, the storage uses it to synchronize the LUNs, vCenter server uses it to manage the hosts of the second site, the VMs use it to communicate with each other. You get the drill, this is not an area to save money on.
Losing the ISL or part of it can be destructive as you might end up in a “split brain” situation where each site thinks the other one is dead and tries to take ownership of the LUNs ending up in 2 sets of data in existence which eventually ends up in restoring from backup.
The impact can be mitigated, according to which storage solution you decide to implement, if it includes a witness (Quorum) component residing in a third site or in the cloud that will act as a broker.
The big names of storage virtualization (again like EMC’s VPLEX) have clever ways to prevent data corruption by having a preferred site and Read-only LUNs but these come at a price.

Even with the best storage replication in the world, it is always recommended to have at least 2 different geographic paths at your disposal for your ISL. Most professional ISP offer, but make sure your does before going ahead with them. Some people think that this is a waste of budget “because the link will never go down”… It will. It only takes one road work that was dug at the wrong spot to take down your ISL and give you major headache trying to get the service back online.
Latency on the ISL
What differentiates synchronous and asynchronous storage replication is the moment when the acknowledgment of a write operation is sent.
Asynchronous
When a storage that uses asynchronous replication receives a write operation, as soon as the IO is written to disk, the acknowledgement that it’s been done is sent immediately back to the host that can then go on with its next IO, the time to replicate the write to the second array is not taken into consideration.

Synchronous
The storage configured to replicate synchronously operate slightly differently. As opposed to the asynchronous method, the storage will wait for the write to be committed to the replicated system before issuing the write acknowledgement to the host.

I bet you can see where I am going with this. It means that whatever the latency is on the ISL (2 and 3) it will be added to every single disk operation of your VMs. So if your ISL has a latency of 50ms, an IO that would have a latency of around 2ms in asynchronous mode will now have 52ms.
Of course, I took a ridiculous example as no sane person would go synchronous with 50ms between the sites. This is the reason why lots of storage vendors issue recommendations and prerequisites in regard to the latency on the link to prevent you from killing your performances and blaming the storage. The maximum RTT for a synchronous storage is 10ms but vendors often require 5ms, EMC requires 1ms for its uniform configuration.
You can get a rough estimate of the latency you would get for a given distance with this calculator.
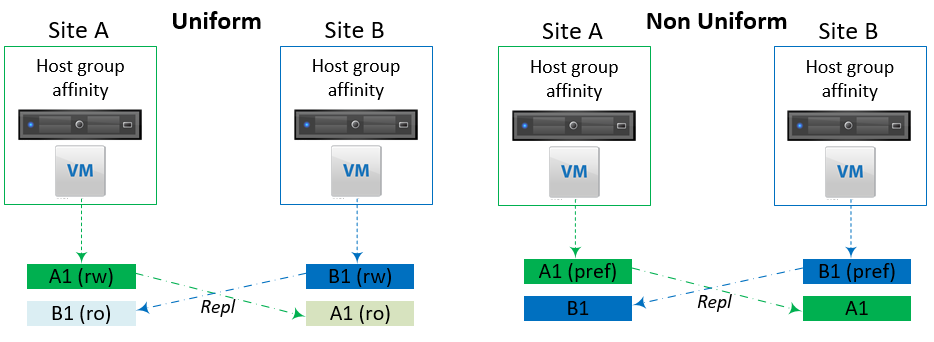
Uniform vs Non-uniform host access
This one is less obvious when it comes to stretching storage across sites. You may think that “Storage is storage” and you just magically present one virtualized datastore to your hosts and that’s it. It is true in a sense but there are 2 main different ways to present the storage and it is important you know why you are choosing which.
The difference between uniform and non-uniform lies in whether you present to the hosts the storage of the remote site or not, and which LUNS can be written to. You can find detailed information about failure scenarios here.
I won’t give any recommendation or preferences in regard to which one you should choose as it is a good old “it depends” as always.
Uniform
In this model, the hosts have paths to the storage cluster on both sides and a LUN can be written to on one of the two sites. It means that if a host in site B wants to write on a LUN that is “owned” by the storage of site A, all the write operations will cross the ISL.
The storage then replicates the change to the second array in a hidden read-only state. This is interesting as it will allow a host to run a VM off the storage of an array that is located on the remote site.
One of the applications of this is in the situation where you lose all the ESXi hosts on one site but not the storage, your VMs will be automatically restarted on the other site. If you lose only the storage of one site, the LUN ownership will be transferred to the surviving site and the hosts will keep accessing the datastore.
The downside of this is that if you don’t pay attention to where you place your VMs you may end up creating a lot of traffic on the Inter Site Link where VMs in site B run off a LUN in site A.
Also due to the fact that there will likely be a lot more cross traffic, the latency requirements are significantly lower than with non-uniform host access. VPLEX requires 1ms for this to be supported!

Non-Uniform
Here the hosts only have paths to the storage of the local site and only access this one. When hosts from site A and site B write to the same datastore, they will write on the LUN in their own site and the storage solution (e.g. vplex) handles the cache state of the volume and replicates the changes in the background. One of the strengths of this model is that regardless of the location of the host the VM runs on, it will access its storage on its local site, hence reducing unnecessary load on the ISL. This is why in non-uniform host access you can get away with a higher latency on the ISL than with uniform, which might very well be a deciding factor.
However in order to avoid data corruption in case of an issue on the ISL (split brain scenario), one site will take ownership of every replicated LUN so if the two storage systems can’t communicate anymore, the LUNs that are not on their preferred site will be placed in an I/O failure state, sending the LUN in a PDL state in vSphere which will trigger HA to restart them on the other site. The VMs on the LUNs located on the preferred site will keep working as usual. For this reason, VM locality is still very important, be it in regard to its storage or its host.
Non-uniform host access

Use DRS
The use of DRS affinity rules in a Metro Cluster is very important and is related to the previous chapter about the host access method. Choosing one over the other will very much depend on you and your ISL, however, whether you go for uniform or non-uniform, you should be using DRS and storage DRS for performance and redundancy reasons.
The idea here is to keep one set of VMs running on the hosts of one site and residing on the datastores mounted on the LUNs that have the same site as preferred. The same obviously applies to the second site. You absolutely don’t want to leave DRS with its default settings, otherwise, you will see VMs traveling on the ISL by themselves and you’ll have no idea what to expect the day things go south!
Datastore clusters
A good idea may be to create 50% of your LUNs with a site affinity on A and the rest of them with a site affinity on B. Name the datastore with an indicator of which site their LUN has the affinity on (e.g. DS-TIER1-A01). You can then create a datastore cluster for each Tier/site combination (e.g. SDRS-T1-A) in which you add the associated datastores.
DRS Host groups
The name of the hosts should also tell you in which site they reside (e.g. ESX-PROD-A01). Create a DRS host group with all the hosts in site A (e.g. DRS-A).
VM placement
Once the LUNs/Datastores and the hosts are properly identified you can start assigning VMs to Datastore clusters and DRS Host affinity rules. When you want to pin a VM to site A, add it to the list of VMs that should or must (according to your needs) run on hosts members of “DRS-A” and store it on “SDRS-T1-A”. You will want to do this for each VMs working in clustered or pooled way like a bunch of web nodes and spread them on both sites. Avoid using the VM Distribution parameter in your DRS cluster as it could disregard your affinity rules.
Resources utilization
I don’t know if this is a thing but I am going to call it the “Why are we not using more resources” Syndrome. If you are planning a Metro-Cluster, this is most likely because you want to be able to survive the loss of one site. Which means if you lose one site you will have a lot of things to restart (or migrate in case of planned maintenance) on the second site. Which means that if you use more than 50% of resources on both sites, there are some things that won’t get to be restarted.
All this makes sense from a technical standpoint, but one day your IT manager, going through the numbers, will show up at your door like “Hey, Why are we not using more resources? The hosts are barely hitting 50%”.
Well, try to pour the content of the first glass into the second one without overflowing it…

However, it would not be accurate to say that you should not be using more than 50% of the overall capacity as a lot of things may not need to be restarted for several different reasons like:
- Non-prod, development, staging, UAT workloads
- Some core infrastructure servers that replicate with each other (LDAP, DNS, WSUS…)
- Servers clustered at the app level (Web nodes, middle tier nodes…), make sure one site’s worth of these can handle full capacity or accept degraded operations
With that said, if you do want to use more than 50% and rely on the fact that the VMs mentioned above will not be restarted, it will be crucial that you do not forget to configure the HA restart priority on all the VMs. Those that will be left for dead must have HA restart priority set to disabled in the VM override settings.

Conclusion
Implementing a Metro-Cluster can definitely make your infrastructure a lot more tolerant to outages but the risk is to think that you are covered by just having stretched storage and that you have nothing to worry about. Planning for a Metro-Cluster is a very interesting process as well as the implementation of it as it pushes the architect to really understand all the different components and think about each and every failure scenarios. If you are unsure about which way to go regarding the storage, it is highly recommended that you speak with your storage provider for advice and supported configurations.
Related Posts:
VMware vSphere management cluster role and benefits
Virtual Machine Load Balancing with Hyper-V Failover Cluster
How to Install Failover Cluster in Windows Server 2016
Follow our Twitter and Facebook feeds for new releases, updates, insightful posts and more.